AI-Augmented Access Certification: Cutting Campaigns from 3 Weeks to 3 Days 2026
Quarterly access certification campaigns are the operational backbone of IGA — and the place where certification fatigue does the most damage. The 2026 enterprise reference on what AI actually automates in certification (not the vendor-marketing version), where the time savings come from operationally, and where AI-augmented certification breaks if you skip the architectural discipline.

Quarterly access certification campaigns are the operational backbone of IGA — and the place where certification fatigue does the most damage. The 2026 enterprise reference on what AI actually automates in certification (not the vendor-marketing version), where the time savings come from operationally, and where AI-augmented certification breaks if you skip the architectural discipline.
- Vendor marketing says 'AI-driven certification.' The operational reality is four specific things AI does in 2026 deployments: risk-stratify entitlements (auto-approve vs careful review vs auto-remove), surface anomalous entitlements (this user has access nobody else in their role has), attest behaviorally (entitlement was used recently vs dormant), and group similar decisions (review 47 analogous grants as one decision).
- The time savings come from one structural change: instead of reviewers attesting line-by-line on flat lists, reviewers triage AI-flagged categories — auto-approve the routine, audit the anomalous, decide the ambiguous. The median 3-week campaign compresses to 3 days because most reviewer time wasn't spent deciding; it was spent reading lists.
- AI in certification works only when three architectural preconditions are met: clean identity catalog (every entitlement has an owner, a justification, a role basis), behavioral telemetry (entitlement usage data flows back to the IGA layer), and reviewer trust calibration (reviewers understand what auto-approval means and what they're attesting to with AI recommendations).
- The dominant failure mode is attestation-fatigue acceleration — when AI recommendations are deployed without discipline, reviewers learn to click through auto-recommended decisions without engagement. The result is worse than no AI: faster sign-off on findings reviewers didn't actually read.
- The 2026 reference architecture composes AI recommendation generation, reviewer-side decision audit (the auditor can verify the reviewer engaged with the AI recommendation rather than just accepting it), behavioral data flow back to the model for continuous improvement, and explicit handling of the 'human is wrong' case where reviewer judgment overrides AI.
Quarterly access certification campaigns are the operational backbone of IGA. Every regulated organization runs them. Every audit cycle depends on them. Every reviewer who's been through one knows the experience: a flat list of entitlements, line-by-line attestation, three weeks of calendar time, the strong temptation to click 'approve' on entries the reviewer doesn't have the context to evaluate. The result is technically a completed certification — but the operational value of the attestations is uneven at best.
The 2026 architectural answer is AI-augmented certification. The vendor-marketing framing is "AI-driven certification" without much specificity about what the AI actually does. The operational reality is four specific things AI does in certification campaigns, and they compose into a time compression that often takes a 3-week median campaign down to 3 days. The piece you're reading is the 2026 enterprise reference on what AI actually does, where the time savings come from, what architectural preconditions have to be in place, and where the pattern breaks if you skip the discipline.
The Avatier history with AI-augmented certification runs deep — the post on Revolutionizing the Way Your Enterprise Conducts Access Certification Audits on avatier.com covers the operational pattern in detail and predates much of the current vendor coverage. This piece extends the framing into the 2026 architecture: how AI-augmented certification composes with the rest of the IGA stack, where it intersects with ITDR and ISPM, and what reviewer-side disciplines keep the time savings real rather than illusory.
 Same entitlements, same reviewer, same outcome rigor. The change is where the reviewer's attention goes — to the decisions that need a human, not the decisions that don't.
Same entitlements, same reviewer, same outcome rigor. The change is where the reviewer's attention goes — to the decisions that need a human, not the decisions that don't.
What AI actually does in certification, mechanically
Four operational capabilities define what AI augmentation in certification looks like in 2026 deployments. Each is concrete and verifiable in the IGA platform's audit log — none requires accepting vendor framing at face value.
Risk stratification. The AI evaluates every entitlement up for review against the user's role context, the entitlement's sensitivity, the user's recent risk signals, and the entitlement's documented justification. Each entitlement gets a recommendation: auto-approve (the AI is confident the entitlement is appropriate, the user's role context matches, no risk signals are elevated), careful review (the entitlement is appropriate but not unambiguously routine), or auto-remove (the entitlement is dormant, no longer matches the user's current role context, or violates a documented policy). The reviewer sees the recommendations and can override any of them; the AI doesn't decide unilaterally.
Anomaly surfacing. The AI compares each user's entitlements against the entitlement patterns typical of users in the same role, organizational unit, or peer group. Entitlements that are unusual for the user's context get flagged for explicit review — "this user has admin access to a system nobody else in their team has access to" is exactly the kind of finding that historically slipped through line-by-line attestation but doesn't slip through anomaly surfacing.
Behavioral attestation. The AI annotates each entitlement with usage data from target systems: when was this entitlement last exercised, how often is it exercised on average, what's the trend. The reviewer sees not just "the user has Salesforce admin access" but "the user has Salesforce admin access, used 47 times in the last 90 days, primarily on configuration administration." Dormant entitlements get flagged with the same precision — "this entitlement was last exercised 18 months ago and the user's role no longer requires it." Behavioral data turns a static catalog review into a usage-informed review.
Bulk decision grouping. The AI groups similar entitlements into bundles the reviewer can decide together. Forty-seven similar Salesforce role grants for new analyst hires don't need to be 47 individual decisions; they're one decision the reviewer applies to the whole bundle. A reviewer can take a position on the bundle in seconds rather than working through 47 lines of nearly identical text. The grouping is conservative — the AI doesn't group entitlements that have meaningfully different risk profiles, even if they look superficially similar — so the bundles are decision units, not noise reduction.
The four capabilities compose. Risk stratification frames the reviewer's attention. Anomaly surfacing flags what needs careful look. Behavioral attestation informs each decision with usage context. Bulk grouping handles the routine cases efficiently. The reviewer's time goes to where it produces value; the AI handles the rest.
Where the 3-week-to-3-day compression actually comes from
The dramatic time-compression numbers in 2026 AI-augmented certification deployments aren't magic. They come from one structural change: the reviewer's time stops being spent reading and starts being spent deciding.
In traditional certification, the campaign distributes flat lists to reviewers. The reviewer opens the list, scans the entries, identifies the handful that need real attention, and clicks 'approve' on the rest with low engagement. Most of the calendar time isn't actually decision time — it's scheduling time (the reviewer's calendar can't accommodate a 3-hour focus block right away), context-switching time (the reviewer needs to remember what each entitlement means before deciding), and the operational overhead of completing the campaign in chunks across several weeks.
In AI-augmented certification, the structural pattern changes. The reviewer opens the campaign and sees three stratified categories: auto-approve recommendations (skim, spot-check, accept), careful-review flags (the small set of entitlements the AI specifically wants the reviewer to examine), and auto-remove recommendations (the dormant entitlements the AI wants to clean up). The reviewer's decision count drops by an order of magnitude. The decision quality on the remaining decisions goes up because the reviewer has the AI's annotation context (usage data, anomaly signals, peer comparisons) to inform each decision. The campaign can complete in a few focused sessions rather than dragged out over weeks.
The compression isn't free — the IGA platform has to do the analytical work that pre-stratifies the campaign, the reviewers have to be trained on the new pattern, and the architecture has to support reviewer override of AI recommendations. But when the preconditions are in place, the time savings are real and verifiable.
The architectural preconditions
Three preconditions have to be met for AI in certification to add value rather than noise. Skipping any of them produces deployments that look like AI-augmented certification but don't deliver the benefits.
Clean identity catalog. Every entitlement has an owner, a documented business justification, a role basis, and a sensitivity classification. The AI's risk stratification depends on the catalog data being clean. Inconsistent cataloguing — some entitlements with detailed metadata, others with stub records — produces inconsistent AI recommendations. The architectural test is whether the catalog can answer "what is this entitlement for, who owns it, and what role bases it" for every entitlement in the inventory. If the answer is uneven across the catalog, AI augmentation will be uneven.
Behavioral telemetry. Entitlement usage data flows from target systems back to the IGA layer in something approaching real-time. Without usage data, the AI can't distinguish "used regularly" from "dormant," and behavioral attestation collapses. Many enterprises have telemetry available in target systems but not integrated into the IGA layer — the operational gap is integration, not data availability. Closing the gap is high-leverage; it's often the single highest-impact improvement available to a certification program.
Reviewer trust calibration. Reviewers need to understand what auto-approval actually means (the AI's confidence the entitlement is appropriate plus the reviewer's attestation that they reviewed the AI's recommendation), what they're signing off on when accepting AI recommendations (the auditable record shows the reviewer engaged), and how to override the AI when their judgment differs (the override path is documented, used in training, and audited for over-reliance on AI). Without trust calibration, reviewers either pattern-click through AI recommendations (attestation fatigue) or second-guess every recommendation (eliminating the time savings).
The three preconditions compound. Clean catalog without telemetry leaves the behavioral signal absent. Telemetry without catalog produces noise the AI can't structure. Both without trust calibration produces an architecturally sound system reviewers don't use well. The mature 2026 deployments invest deliberately in all three.
 Three preconditions, one foundation. Each is necessary; none is sufficient alone. The compression depends on all three being operationally mature.
Three preconditions, one foundation. Each is necessary; none is sufficient alone. The compression depends on all three being operationally mature.
Where AI-augmented certification breaks
Three failure modes recur in 2026 incident reports from AI-augmented certification deployments. Each has a known mitigation; the failure is usually skipping the mitigation rather than not knowing it exists.
Attestation-fatigue acceleration. The dominant failure. When AI recommendations are deployed without reviewer engagement controls, reviewers quickly learn that the AI's recommendation is usually right, that the AI handles the routine cases, and that they can mostly click 'approve' on AI-recommended decisions without examining them. The result is worse than no AI: the campaign completes faster, but reviewers signed off on findings they didn't actually engage with. Auditors who probe the engagement (asking reviewers about specific decisions) find blank looks. The mitigation is enforcing reviewer engagement — auditable evidence that the reviewer actually examined the AI's recommendation (mouse hover patterns, time-on-decision metrics, periodic 'why did you approve this' challenges), mandatory pause on the highest-risk categories (no auto-approval cascade allowed without explicit reviewer engagement), and periodic reviewer engagement audits that surface reviewers who pattern-click.
Model drift. The AI's recommendations are calibrated against historical data. The historical data ages. New role types emerge that the AI doesn't have ground truth on. New applications enter the environment that the AI hasn't seen before. New business contexts shift the meaning of access patterns. Without continuous model refresh, the AI's recommendations slowly diverge from current organizational reality. The mitigation is treating the AI model as a deployed system that needs ongoing maintenance — periodic retraining against current data, explicit handling of 'no prior data' cases (the AI defers to the reviewer rather than guessing), and quality metrics that surface drift before it produces wrong recommendations.
The 'AI was wrong' incident. The AI auto-approved access that should have been flagged, or recommended removal of access that should have been kept. The IGA platform has to support recovery (the access is restored or removed cleanly), override (the reviewer's judgment overrides the AI's recommendation cleanly), and learning (the case is fed back into the model so similar cases get handled correctly next time). The 2026 architecture treats AI recommendations as suggestions, not decisions — the reviewer's attestation is the authoritative outcome. When AI is wrong, the architecture treats it as a learning opportunity, not a catastrophic failure.
The three failure modes are operationally manageable when treated as design constraints. The deployments that don't treat them as design constraints — that deploy AI recommendations without engagement controls, without model refresh, without explicit override and learning paths — produce the kind of incident reports that show up when auditors get assertive.
How this composes with ISPM, ITDR, and the broader IGA stack
AI-augmented certification is one layer of the 2026 IGA stack, not the whole thing. The composition matters because the layers reinforce each other.
Certification + ISPM. ISPM (Identity Security Posture Management — covered in the ISPM piece) runs continuously between campaigns, surfacing findings the campaign cycle would miss — orphaned admin accounts, configuration drift, dormant entitlements that emerged between campaigns. Certification campaigns are the periodic deep review; ISPM is the continuous shallow audit. Together they cover both temporal patterns.
Certification + ITDR. ITDR (Identity Threat Detection and Response — covered in the ITDR piece) watches for active threats against authenticated identities. ITDR's behavioral baselines can feed certification's anomaly surfacing — a user whose recent behavior triggered ITDR flags should also see their entitlements scrutinized more carefully in the next certification cycle. The integration is bidirectional: certification findings inform ITDR baselines, ITDR signals inform certification scrutiny.
Certification + HRIS-driven lifecycle. HRIS-driven lifecycle (covered in the HRIS-Driven Lifecycle piece) handles the joiner-mover-leaver workflow that prevents entitlement accumulation in the first place. Certification catches what slipped through; lifecycle prevents most of what slips. The mature deployment uses both — strong lifecycle automation reduces the volume of entitlements certification has to review, and certification catches the cases lifecycle didn't.
Certification + the broader IGA platform. The Best IGA Solutions buyer guide covers the IGA platforms that host the certification capabilities this piece describes. The architectural test in 2026 procurement is whether the platform's AI-augmented certification meets the four-capability bar (risk stratification, anomaly surfacing, behavioral attestation, bulk grouping) and whether the architectural preconditions (clean catalog, behavioral telemetry, reviewer trust calibration) can be operationally met in the buyer's environment.
The 2026 reference path
Build the architectural preconditions before deploying AI recommendations. Clean the identity catalog so every entitlement has an owner, justification, role basis, and sensitivity classification. Integrate behavioral telemetry from target systems into the IGA layer. Train reviewers on the AI-augmented pattern and calibrate their trust through explicit guidance about what auto-approval means and when override is appropriate.
Deploy the four AI capabilities together. Risk stratification, anomaly surfacing, behavioral attestation, and bulk decision grouping compose; deploying one or two of them produces partial benefits. The full compression requires the full capability set.
Enforce reviewer engagement explicitly. Mouse-hover patterns, time-on-decision metrics, periodic challenge questions, mandatory pause on highest-risk categories, audits that surface pattern-clickers. The discipline is what keeps the time savings real rather than illusory.
Maintain the AI model as a deployed system. Continuous retraining, drift monitoring, explicit handling of novel cases, recovery paths when the AI is wrong. The AI is a tool, not an oracle; treat it like infrastructure that needs ongoing maintenance.
Compose with the broader stack. AI-augmented certification is the periodic deep review; ISPM is the continuous shallow audit; ITDR is the real-time threat layer; HRIS-driven lifecycle is the preventive automation. All four together produce the 2026 reference identity-security envelope. The certification piece, properly deployed, compresses 3 weeks to 3 days — but the compression is most valuable when the rest of the stack is also operational.
AI in certification is one of the highest-leverage operational improvements available to enterprise IGA programs in 2026. The technology is mature, the patterns are settled, the operational discipline is well-understood. The implementation gap is mostly the architectural preconditions — clean catalog, behavioral telemetry, reviewer trust calibration — and the engagement discipline that keeps the savings real. Close those gaps deliberately, and the 3-week-to-3-day compression follows.
ABOUT THE AUTHOR

More from IAM & Identity Governance

Shadow IT Provisioning: The Access Risk Living in Your Ticketing System 2026
Most enterprise access doesn't flow through the IGA platform — it flows through Slack DMs, ServiceNow tickets routed to direct grant, manager spreadsheets, tool-side admin self-service, and vendor SaaS self-provisioning. The 2026 enterprise reference on shadow IT provisioning, why it bypasses even mature IGA programs, and the architectural pattern that captures it without breaking the operational flow.
Identity Security Posture Management (ISPM) for Enterprise 2026
ISPM is the emerging analyst category that sits above IGA and beside ITDR — the preventive posture audit, drift detection, and identity-asset inventory layer that answers 'is our identity infrastructure currently configured the way our policy says it should be.' The 2026 enterprise reference on the evaluation domains, vendor landscape, and integration architecture.
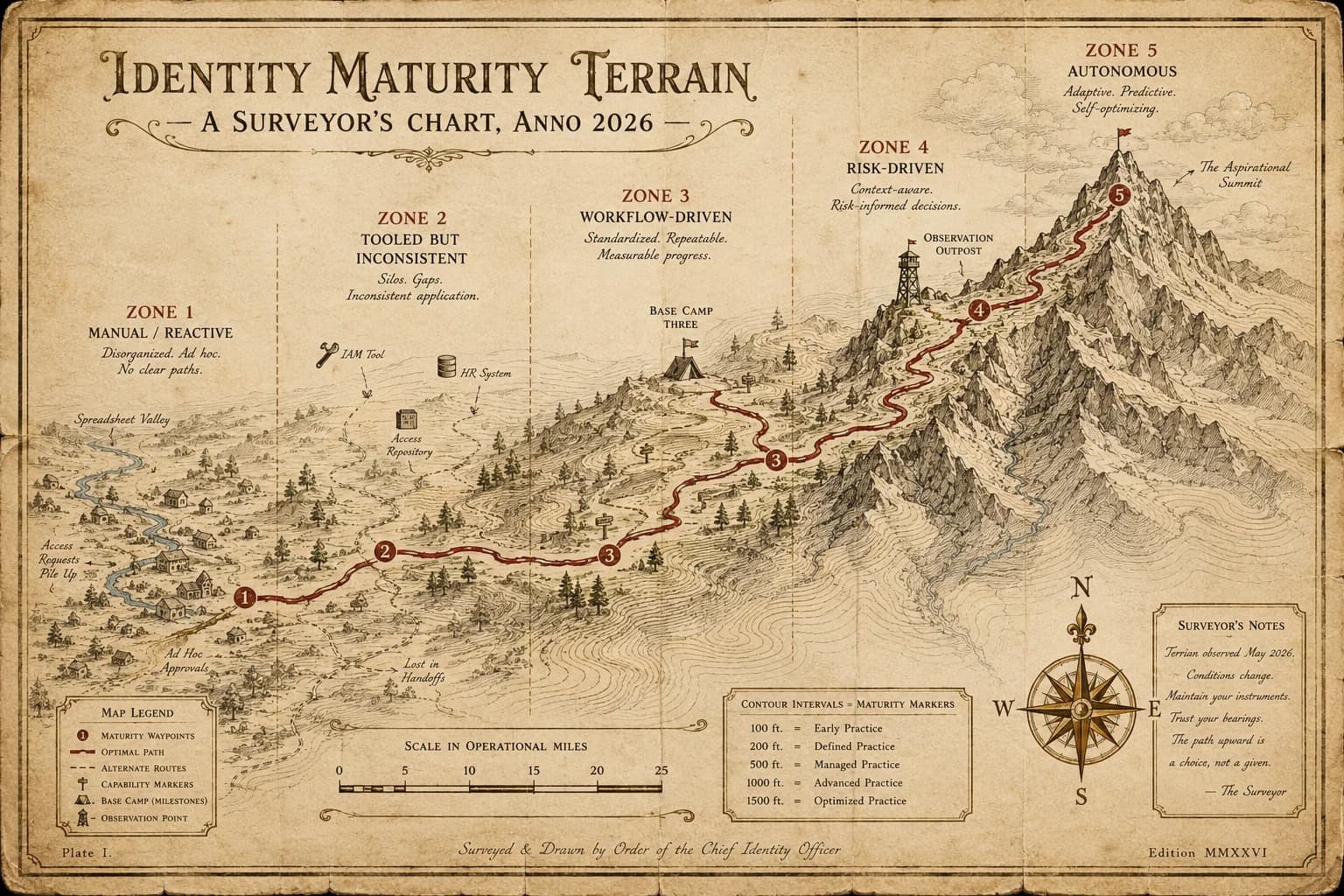
The Identity Maturity Model: Where Does Your Organization Actually Stand 2026
Every enterprise identity program sits at one of five maturity stages — from manual and reactive at Stage 1 to autonomous and AI-augmented at Stage 5. The 2026 enterprise reference on the five-stage model, the self-assessment criteria that locate where you stand, and the operational moves that get you to the next stage.